How Many Folds for Cross-Validation
Introduction
Cross-validation (CV) is a method for estimating the performance of a classifier for unseen data. With K-folds, the whole labeled data set is randomly split into K equal partitions. For each partition, the classifier is trained on the remaining K-1 partitions and is tested on data from that partition. The final accuracy is the average of all K accuracies.

Figure 1: Example of 5-fold cross-validation.
How many folds should we pick?
The question is which value of K we should pick. Higher values of K give less biased estimation. In theory, the best value of K is N, where N is the total number of training data points in the data set. N-fold CV is also called Leave-One-Out Cross-Validation (LOOCV). Although LOOCV gives unbiased estimate of the true accuracy, it is very costly to compute.
In practice, we usually use K = 5, 10 or 20 since these K-fold CVs give approximately the same accuracy estimation as LOOCV but without costly computation.
The Figure 2 shows Ron Kohavi’s experiment with CV using different values of K for the decision tree classifier C4.5 on different data sets. The gray regions indicate confidence intervals for the true accuracies. The negative K stands for Leave-K-Out.
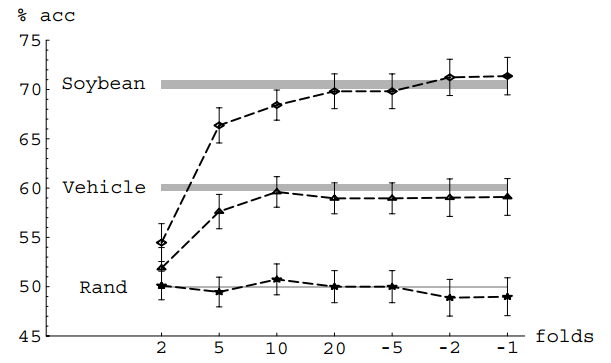
Figure 2: Ron Kohavi. A study of cross-validation and bootstrap for accuracy estimation and model selection. IJCAI '95. PDF
My experiment
Here is the Python code to replicate Ron Kohavi’s experiment on the Iris data set:
As we can see in the Figure 3, the good value of K is 10 since it gives the best trade-off between the running speed and the accuracy estimation.
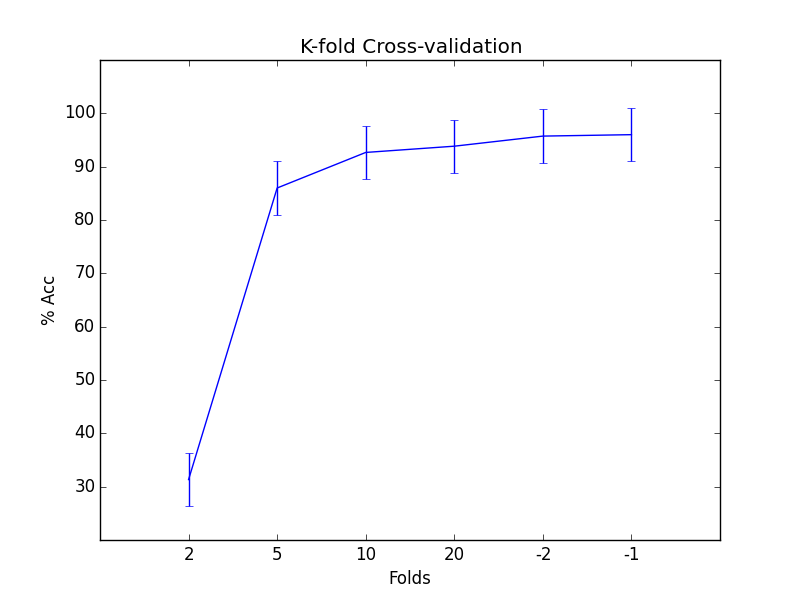
Figure 3: Cross-validation experiment on the Iris data set.</p> </div>